As a researcher, I have to keep myself up-to-date with latest research in my field. Given the pace with which deep learning research is moving currently, it has become quite a gargantuan task lately. Large quantity also brings a lot of noise with it.
While, whether certain works should really be published is a matter of discussion for another day! As a researcher it has become quite impossible to read each and every one of papers that show up on Arxiv in the my field of deep learning, computer vision and pattern recognition.
Updated additional plugins: Zutilo - for managing tags, keyboard shortcuts etc., ZoteroQuickLook to use OSX like quick look features. Also updated the exact settings of the Zotfile plugin.
During my PhD, I was able to track all papers I read simply by organizing them in topic-wise folders and sub-folders for read vs unread. That is simply not an option today. I will simply loose my brain or just give up reading. This led me to start looking into proper tools (or tool sets) that could enable me manage this in a sane manner. Some of my required features (in order of importance) were:
- filter relevant papers fast
- store them conveniently at some location that can be easily accesses from all of my devices
- pdf annotator and syncing of annotations
- personal rating of papers
- tagging of papers
- works on Linux, OSX and iPad
- share easily with my colleagues
My search brought me to the following set of free (and some paid) tools. In this post, I want to illustrate my sweet setup. I hope this could be of help to a lot of researchers in this field like me.
Filtering Relevant PapersSection titled Filtering Relevant Papers
This is the era of machine learning. My first thought - can’t we apply ML to find me relevant papers on ML! That quickly brought me to Arxiv Sanity by @karapathy. Project description of github says it all:
This project is a web interface that attempts to tame the overwhelming flood of papers on Arxiv. It allows researchers to keep track of recent papers, search for papers, sort papers by similarity to any paper, see recent popular papers, to add papers to a personal library, and to get personalized recommendations of (new or old) Arxiv papers. This code is currently running live at www.arxiv-sanity.com, where it’s serving 25,000+ Arxiv papers from Machine Learning (cs.[CV|AI|CL|LG|NE]/stat.ML) over the last ~3 years.
To summarize: this lets me filter arxiv papers based on tags relevant to me. Then, using SVM models based on my choices, recommends new and past papers. Additionally, you can get popular (based all user’s library), trending (based on twitter), popular among friends papers as well. Talking of friends, if you want me to follow there, please add me to your friend list as “sadanand.singh”.
Now, I have started using this website weekly, I add papers to library and recommendations keep improving. Other source of my relevant papers is twitter! Follow right people and you get a minefield of information.
Management of Papers: Zotero and pCloudSection titled Management of Papers: Zotero and pCloud
Once I have found the right papers, I had to find right tools to manage them. There are commercial solutions for this including readcube, mendeley, papers (now part of readcube). I did not like any of these simply for their business model - high prices, data storage etc. Then I came across an open source offering - zotero.
I instantly fell in love with zotero. It works on all desktop platforms - Linux and OSX. It has two of the most important features that I wanted: tags, central local of storage. However, I soon realized, the free version only supports up to 1 GB of storage. My library is already past 6 GB. To my help, they have support for webdav servers, and my cloud provider - pCloud has native support for webdav! It was pretty easy to setup and voila! Please see the below screenshot for my setup.
Neither Dropbox or Google Drive provide native webdav support. In case, you are considering Zotero, please consider signing up for a free pCloud account. I promise you, you are not going to regret it. I loved it so much that I signed up for their lifetime 2 TB account!
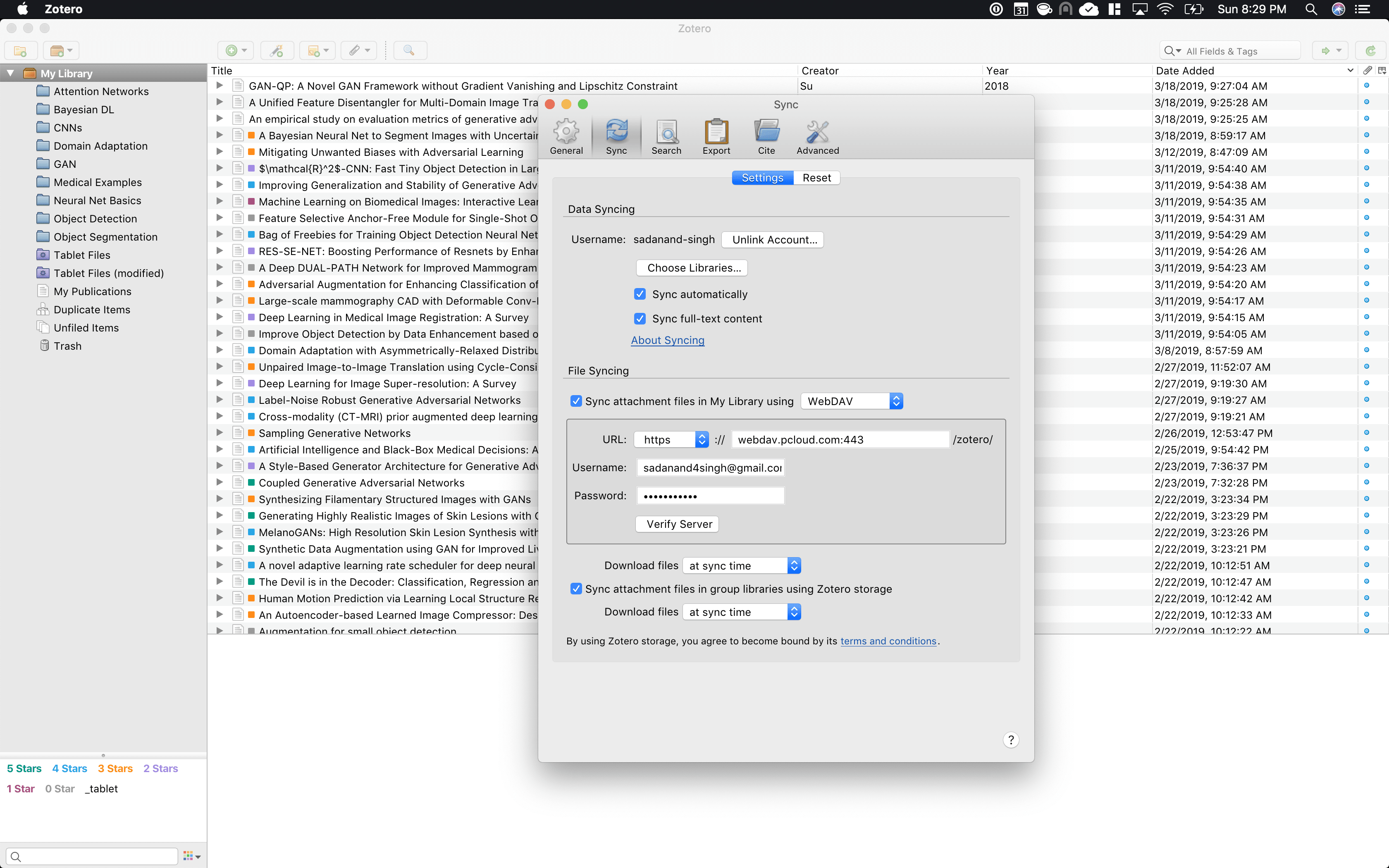
One very interesting feature of zotero is colored tagging. Once you have created a tag, you can right click on it and assign it a color and shortcut numeric key. I use this heavily for rating papers in my library. For example, I can just press 1 to assign a paper a 5-star rating.
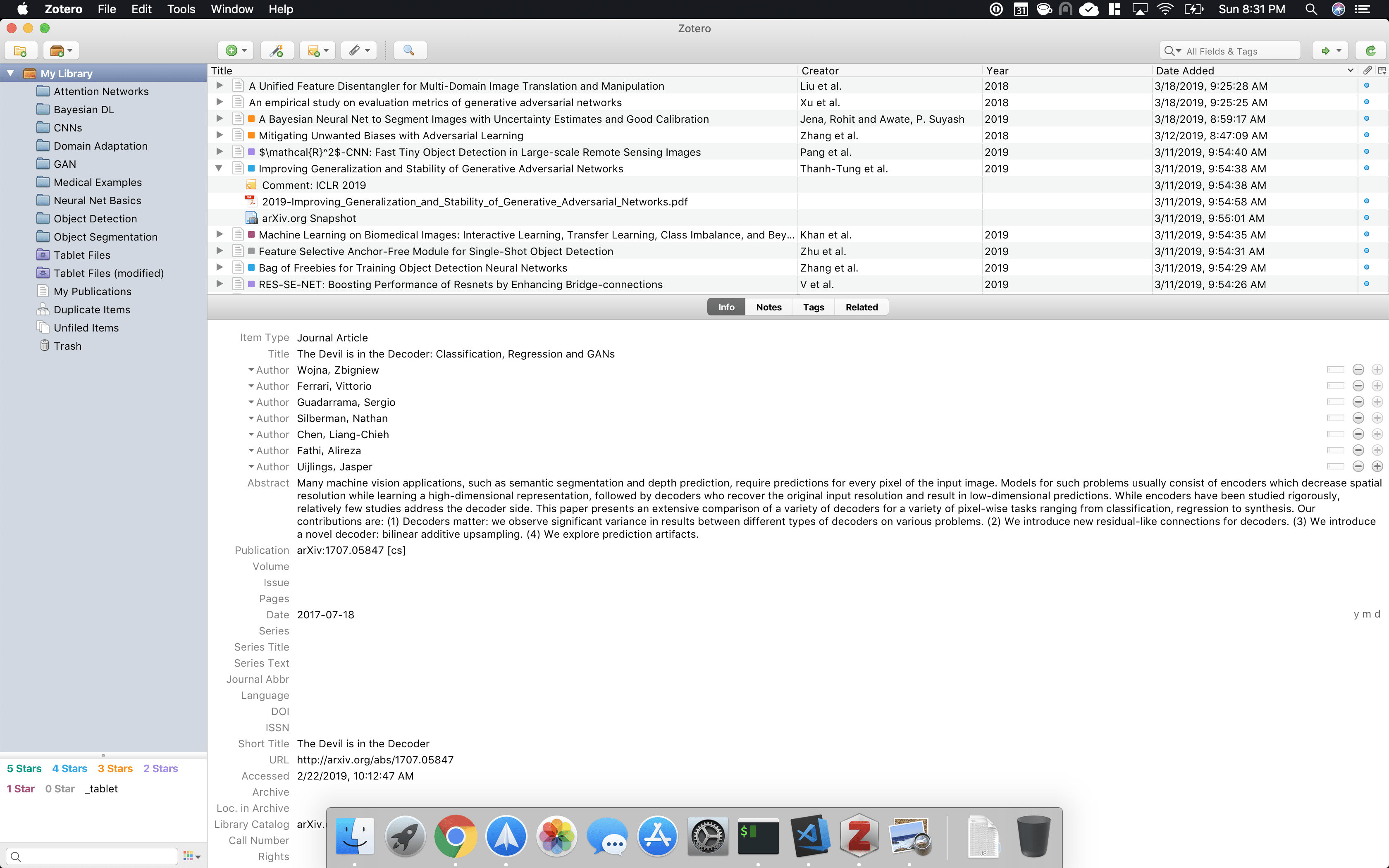
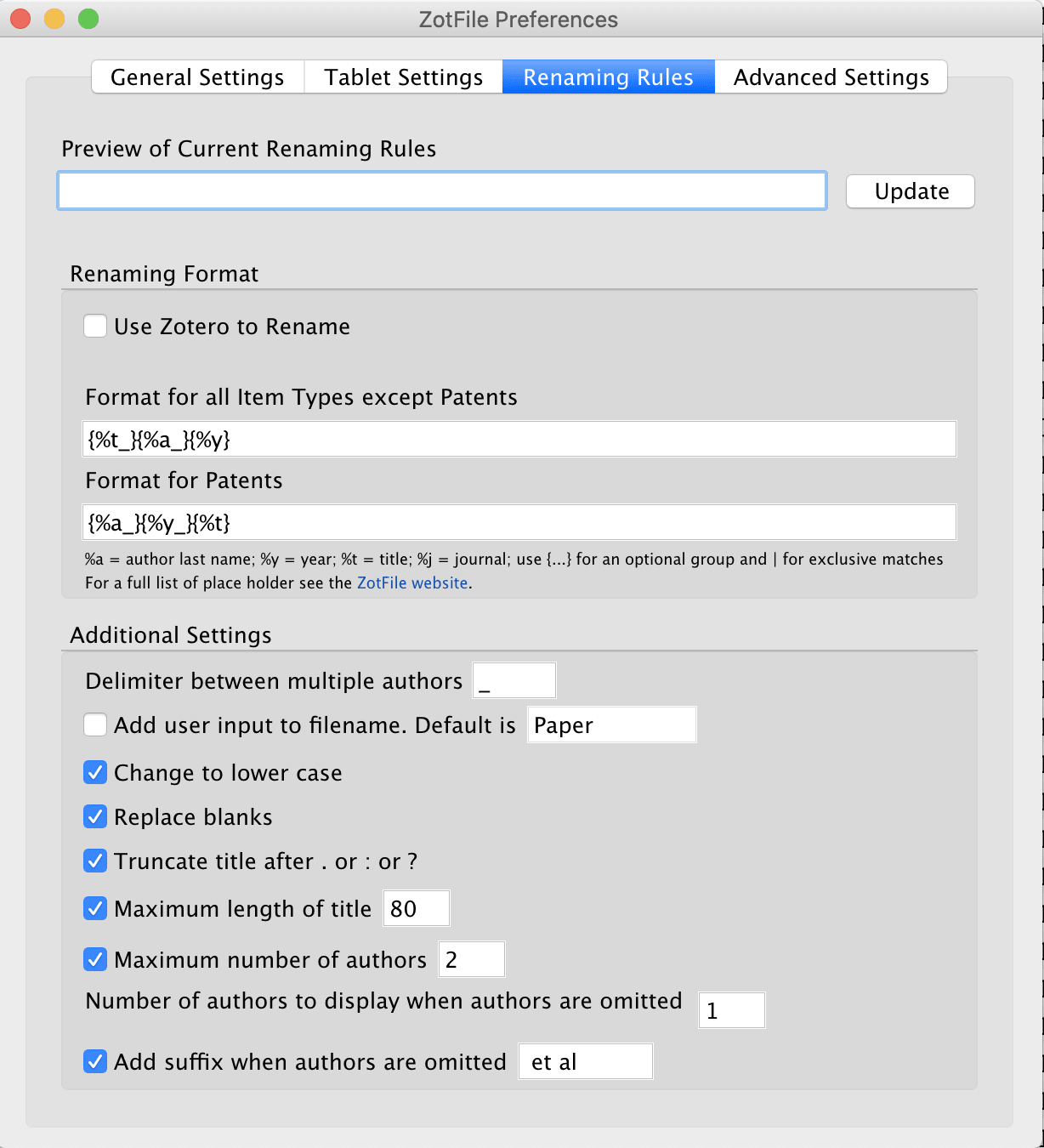
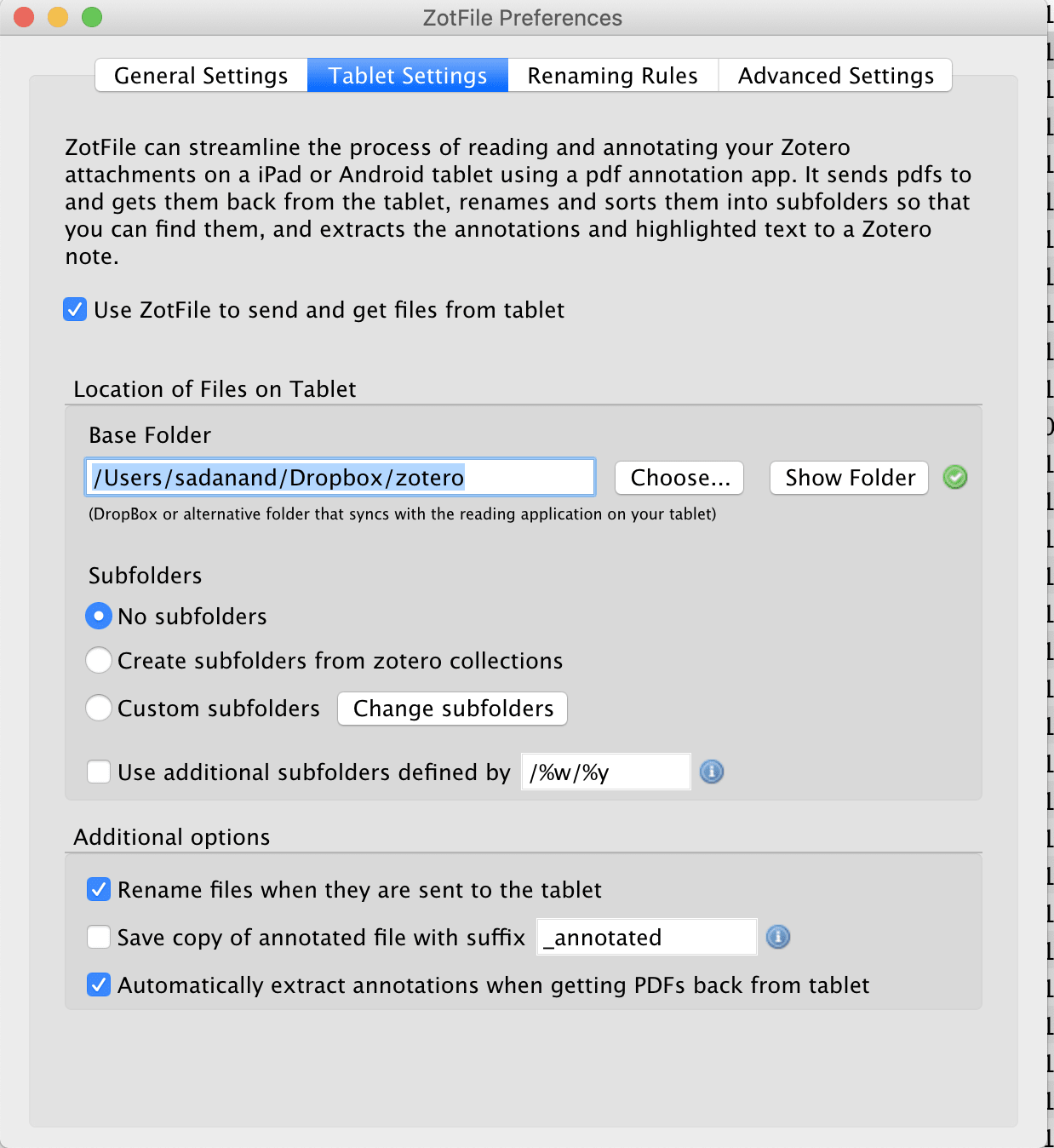
Another feature of zotero that I use it its plugins. Specifically, I use a plugin called ZotFile. This plugin enables me to have a subset of papers from library on my iPad via a cloud folder. Once, I have read, added any annotations on my tablet, I can bring back all the data back to my library.
Here are the screenshots of my exact settings:
On my iPad, I use an app called PDF Expert. This allows me to view my pCloud folder holding my pdfs from Zotfile, as well as read and annotate PDFs quite elegantly.
Another handy plugin that I use is called ZoteroQuickLook. This uses OSX like quick look feature to show details of a reference. All you do is press SPACE on an entry, and you get the following quick preview:

Another plugin that I use is called Zutilo. It adds several functions not available in base Zotero through extra menu items and keyboard shortcuts. Here are some of Zutilo’s features:
- Copy, paste, and remove sets of tags
- Select and right-click to relate several items
- Copy items to the clipboard in several formats
- Keyboard shortcuts for editing items and focusing and hiding different elements of the Zotero user interface
Annotating PDFsSection titled Annotating PDFs
Last thing remaining on my feature list was pdf annotations. On linux, I use foxit reader. It has right tools for annotations and saving them right in the pdf files. On my mac though, I did not like the look and feel of foxit reader on OSX. I ended up going with PDF Expert for Mac. Although, its a paid software, I really love their smoothness and features.
Finally, you can also share any library with your colleagues using the Zotero Groups feature. This enables you to share you library, and discover other people’s library in the team.
COMMENTS